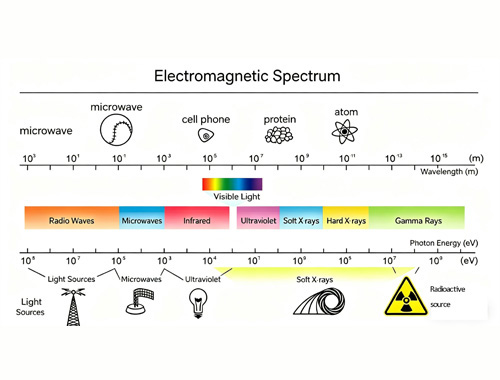
Science Popularization: What Exactly is Repeatability?
In the world of precision motion platforms, repeatability (or repeatable positioning accuracy) is a holy grail. Imagine commanding a stage to move to the exact same nominal position multiple times. Will it land perfectly on the mark every single time? Usually, there is a microscopic discrepancy. Repeatability is the statistical measure of this deviation. Depending on the testing standards applied, engineers calculate this using different statistical methods, such as Peak-to-Valley (PV), 2σ, or 3σ.

However, repeatability isn't dictated by just one variable; it is at the mercy of a highly complex web of factors. These range from the stage's internal mechanics—such as backlash, friction, cable drag, servo jitter, and structural stiffness—to environmental variables like thermal drift, floor vibrations, and even ambient acoustic noise. Quantifying the exact, isolated impact of every single factor is virtually impossible.
Let’s look at a classic example: the "Gap" phenomenon. When a stage moves forward and then reverses direction, backlash and unrecoverable elastic deformation often create a noticeable positional discrepancy between the two directions. While the root causes of backlash are generally attributed to the mechanical connections between parts, unrecoverable elastic deformation is a more tangled web. It occurs when external forces—like static friction and cable tension—engage in a tug-of-war with the motor's driving force. Together, we refer to these two culprits collectively as "unrecoverable structural deformation," as illustrated in Figure 2. In real-world testing, teasing apart the individual contributions of these two factors is incredibly difficult.

(Figure 2: Unrecoverable structural deformation)
Since we cannot pin down a precise mathematical value for every single factor, we turn to statistics and phenomenology to make sense of the test results. By taking this approach, we can categorize the factors affecting repeatability from a statistical perspective, as shown in Figure 3.

(Figure 3: Statistical categorization of factors affecting repeatability)
The Experiment: Hunting Down the Culprits of Repeatability

(Figure 4: Single-axis air-bearing stage)
To find out what's really messing with repeatability, we rolled up our sleeves and conducted an experiment. We randomly selected a typical single-axis air-bearing stage and put it through a series of repeatability tests. The results, shown in Figure 5, were illuminating. We could clearly see the fingerprints of three main culprits: random jitter (Noise), unrecoverable deformation (Gap), and long-term positional drift.

(Figure 5: Typical repeatability test results of an air-bearing stage)
To dig deeper and understand exactly how much weight each factor carries, we utilized test data from an Akribis air-bearing stage. To isolate the variables cleanly, the stage was tested in two different configurations: one with a cable track (drag chain) and one without.

(Table 1: Repeatability test results based on Renishaw 2012 standards (Without cable track))
Using the stringent Renishaw 2012 testing standard, we gathered the data shown in Table 1. But raw numbers rarely tell the whole story at first glance. To uncover the true influencers, we had to mathematically decompose this test data.

(Figure 6: Decomposed repeatability test data (Without cable track))
Once we broke down the data (Figure 6), a clear pattern emerged. Even though the overall repeatability varied from test to test, the impact of random jitter (Noise) and unrecoverable deformation (Gap) remained remarkably stable. The real troublemaker—the reason the overall results fluctuated between runs—was predominantly thermal drift (Drift).
Here is where things get particularly interesting. Because an air-bearing stage floats on a thin cushion of air, it has virtually zero guiding friction. As a result, the physical cables and tracks become the primary source of mechanical disturbance (Noise). To prove this, we ran the exact same tests on the platform, this time with the cable track installed.

(Figure 7: Typical test data with and without a cable track)
The contrast was stark (Figure 7). With the cable track attached, the data took on a distinct, wavy pattern. Without it, the data looked highly linear. Looking at the numbers, the baseline noise without the track was hovering around ±15 nm. But once the track was added, that noise ballooned to approximately ±40 nm—a massive increase. The takeaway? If you are building a motion platform that demands ultra-high repeatable positioning accuracy, the disturbance caused by cable tracks absolutely cannot be ignored.

(Figure 8: Decomposed test data without cable track) (Figure 9: Decomposed test data with cable track)
Conclusion: Elevating Repeatability is Crucial—and a Masterpiece of Systems Engineering
At the end of the day, repeatability isn't just a spec on a datasheet; it is one of the most critical performance indicators for any precision motion platform. It single-handedly dictates the accuracy grade of the final machine. Whether you are engineering a semiconductor inspection tool, a cutting-edge lithography machine, a high-speed pick-and-place system, or an ultra-precision CNC machine, repeatability is always the top consideration.
But as our experiments show, achieving that next level of precision is incredibly challenging. It's never a matter of fixing just one thing. Engineers must carefully orchestrate the placement of linear encoders, the positioning of motors, the mitigation of guide friction, and—as we clearly saw—the seemingly mundane routing of cables. Ultimately, pushing the boundaries of repeatable positioning accuracy is a massive, highly complex exercise in systems engineering.